Synthetic Healthcare Data and AI

September 24, 2025
.png)
Synthetic data is one of the most exciting developments in healthcare research and technology. It offers a way to generate lifelike, privacy-safe patient records that can be used to test AI chart abstraction methods, test clinical software, and run feasibility studies without putting real patient data at risk. Below, we break down what synthetic data is, how it’s used in healthcare, its benefits and challenges, and how it’s revolutionizing the industry.
Key Takeaways
- Synthetic data mimics real data without exposing patient identities.
- It’s used for clinical trial recruitment and feasibility studies, AI model training, software testing, and medical education.
- Benefits include scalability, fairness, and compliance with HIPAA/GDPR.
- Challenges remain in fidelity, trust, and regulatory acceptance.
What is Synthetic Data?
Synthetic data is artificially generated information that mimics real-world data but isn’t collected directly from real people, events, or systems. Instead, it’s created using algorithms, statistical models, or simulations designed to reproduce the patterns, distributions, and relationships found in actual datasets.
- Looks real, but isn’t: It resembles real data in structure and statistical properties (e.g., distributions, correlations), but does not include any identifiable records.
- Multiple generation methods: It can be created through rule-based logic, statistical modeling, or generative AI models like GANs or VAEs.
How is Synthetic Data Used in Healthcare?
Synthetic data is being used in a variety of applications across healthcare, ranging from experimental to productionized.
Research and Development
Synthetic data allows researchers to simulate trial populations, making it easier to check whether inclusion/exclusion criteria are realistic before launching a clinical trial. This is especially useful in clinical trial enrollment and recruitment, where feasibility studies can save months of planning. It can also be used to augment limited datasets, helping model what “missing” populations might look like.
As the U.S. Office of the National Coordinator for Health IT notes: “Synthetic health data can provide a lower risk data source to complement research and support testing needs until real clinical health data are available.”
Training Algorithms and AI Models
AI systems for diagnosis support, LLM chart abstraction, or medical imaging rely on large, diverse datasets for training and validation. Synthetic data expands training corpora, balances under-represented subgroups, and provides rare cases for more robust model development. It’s a powerful tool for developing AI clinical registry platforms and advancing natural language processing for EHR notes.
HIPAA, GDPR, and Regulatory Compliance
Because synthetic datasets don’t map back to real individuals, they offer a strong alternative to traditional de-identification. This enables collaboration and data sharing across institutions while meeting compliance requirements like HIPAA and GDPR.
Software Development and Validation
Healthcare software vendors use synthetic patient records to test EHR modules, clinical trial management platforms, and analytics dashboards. Developers can also generate rare but critical cases to stress-test workflows without exposing real patient records.
Education & Training
Medical students and clinicians can practice diagnosis and decision-making on synthetic patient cases, while data science trainees gain access to lifelike EHR datasets for projects with no IRB or special approvals required.
Benefits of Synthetic Healthcare Data
The primary benefit of synthetic healthcare data is scale: you can generate a lot more data quickly than through other methods. For example, Chen et al. (2021) showed that training a model on 10,000 real images plus 10,000 synthetic images produced equal or improved performance compared to using real data alone.
Other benefits include:
- Privacy: Reduces or eliminates reliance on identified patient data.
- Mimics real data: Provides realistic datasets for testing and training.
- Covers data gaps: Augments rare or under-represented cases.
Challenges of Synthetic Healthcare Data
The main challenge of synthetic data is fidelity, or ensuring it appropriately captures the real-world complexity it's intended to mimic. In one study, Bhanot et al. (2021) found statistically significant subgroup differences (age, race/ethnicity, gender, mortality) between real and synthetic datasets—suggesting synthetic data can inadvertently replicate or even amplify disparities.
Other challenges include:
- Trust: Researchers and regulators need evidence that models trained on synthetic data generalize to real patients.
- Standards: Clear benchmarks for validating synthetic data utility and privacy are still evolving.
How to Leverage Synthetic Data in a Healthcare Setting
Leverage synthetic data requires diligent goal setting, measurement, and iteration to be successful.
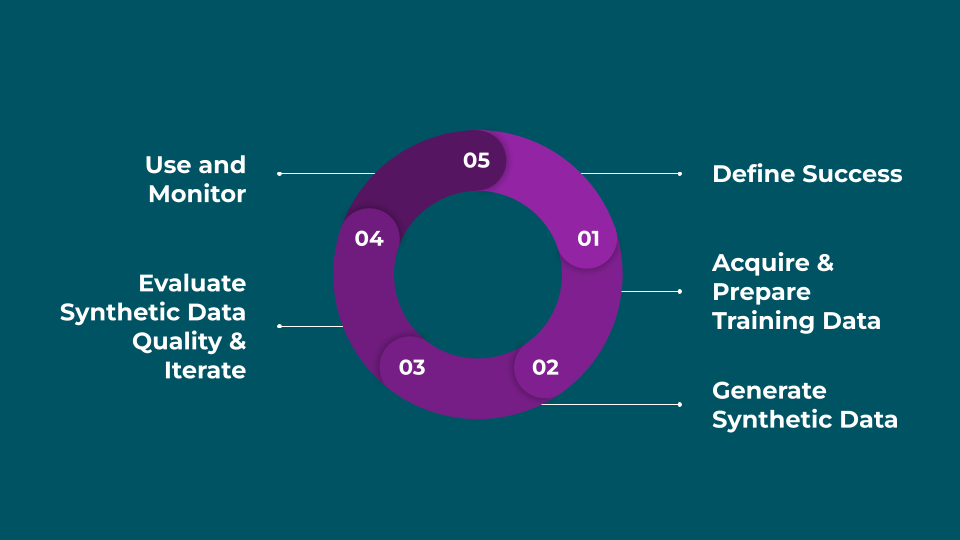
1. Define Success
Clarify the format, volume, and use cases you need for your synthetic data, and decide how you’ll evaluate quality.
2. Acquire & Prepare Training Data
Gather and securely manage the real-world data that will serve as the basis for generating synthetic data. You'll likely need to clean, preprocess, and transform inputs to prepare them for modeling.
3. Generate Synthetic Data
Train statistical or generative models to produce synthetic datasets that mirror the properties of the training data.
4. Evaluate Synthetic Data Quality & Iterate
Assess fidelity, privacy, and utility using the metrics you defined. Adjust training or generation approaches until quality and coverage are sufficient.
5. Use and Monitor
Once the synthetic data reaches your quality standards, begin to use it for trial feasibility, model training, testing, education, or any other use case where it has utility. Designing monitoring systems to detect if there's a problem with the data can help you react quickly.
How Synthetic Data Is Revolutionizing the Healthcare Industry
Synthetic data is transforming the way healthcare systems, researchers, and innovators approach data. For decades, privacy and access barriers have slowed collaboration between hospitals, academic centers, and technology developers. By creating lifelike but non-identifiable datasets, synthetic data removes many of those barriers, enabling institutions to share useful information safely and accelerate discovery. It gives researchers and clinicians the ability to run feasibility checks for clinical trial recruitment, simulate patient populations, and test predictive models without exposing protected health information (PHI). This shift is allowing healthcare organizations to move faster while remaining compliant with HIPAA, GDPR, and other regulatory frameworks.
At the same time, synthetic data is fueling the next wave of AI and machine learning in medicine. Large language models for chart abstraction, natural language processing pipelines, and imaging algorithms all require massive volumes of diverse training data. Synthetic datasets can supply that scale while also filling gaps in underrepresented patient groups or rare conditions. Developers of healthcare software are also leaning on synthetic data to test electronic health record systems, clinical registries, and analytics dashboards—going so far as to simulate rare edge cases that might never appear in a small, real-world dataset. As Giuffrè et al. (2023) notes, “Synthetic data has shown promise … to augment datasets for predictive analytics, enhance data privacy, and inform government policy.”
In short, synthetic data is not just a privacy workaround but a foundational tool that is breaking down silos, enabling innovation, and pushing the healthcare industry into a new era of AI-driven research and clinical care.
Bottom Line
Synthetic data is more than just a workaround for privacy; it’s becoming a foundational building block for research, clinical registries, clinical workflows, and more.
By leveraging foundation models, Brim's chart abstraction pipeline avoids some of the training needs for synthetic data, and our secure deployment in your organization's cloud means that you don't have to de-identify data before using Brim. However, synthetic data can still be useful when accelerating your chart abstraction with Brim: to add rare use cases to data sets, to test out hypotheses about variables and variable systems, or to create additional cases for validation. We use synthetic data internally to monitor quality across different data types so we can ensure a good abstraction experience.
Want to learn more about how Brim is leveraging the latest in AI to make chart abstracton rapid and reliable? Request a demo.
Synthetic Healthcare Data FAQ
Is synthetic data safe and compliant with regulations like HIPAA?
Yes. Properly generated synthetic data doesn’t correspond to real individuals, making it a compliant and safe way to share and use health information.
Can synthetic data replace real patient data in clinical research?
Not fully. It’s best used to augment or simulate scenarios, but real-world validation remains essential.
Is synthetic data accepted by healthcare regulators and institutions?
Acceptance is growing, especially for feasibility studies, education, and software testing. For clinical trials and regulatory submissions, real data is still required, but synthetic data is gaining traction as a complementary tool.